Note
This page was generated from docs/source/notebooks/tutorial.ipynb.
An interactive version of this notebook can be run using Binder by clicking
![]()
Note that if you wish to run this notebook on your own, you’ll need to have matplotlib and seaborn installed.
PyUnfold Tutorial¶
PyUnfold uses the iterative_unfold function to perform iterative
unfoldings. In addition, we’ll use the Logger callback (see the
Callbacks documentation for more information) to
display the unfolding status at each iteration.
In [1]:
from pyunfold import iterative_unfold
from pyunfold.callbacks import Logger
In [2]:
import numpy as np
np.random.seed(2)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
In [3]:
sns.set_context(context='poster')
plt.rcParams['figure.figsize'] = (10, 8)
plt.rcParams['lines.markeredgewidth'] = 2
True distribution¶
Before we can perform an unfolding, we’ll need some true and observed
data. In this tutorial, we’ll use the numpy.random module to
generate some example data. Let’s assume that we are measuring some
observable, \(X\), that is given by a normal (Gaussian)
distribution.
In [4]:
num_samples = int(1e5)
true_samples = np.random.normal(loc=0.0, scale=1.0, size=num_samples)
true_samples
Out[4]:
array([-0.41675785, -0.05626683, -2.1361961 , ..., 2.60578854,
-0.21578792, -0.89995693])
These samples can then be binned to form a histogram of the true distribution.
In [5]:
bins = np.linspace(-3, 3, 21)
num_bins = len(bins) - 1
In [6]:
data_true, _ = np.histogram(true_samples, bins=bins)
data_true
Out[6]:
array([ 218, 478, 977, 1814, 3058, 4898, 6878, 9226, 10712,
11782, 11789, 10814, 8886, 6892, 4759, 3013, 1804, 1009,
497, 228])
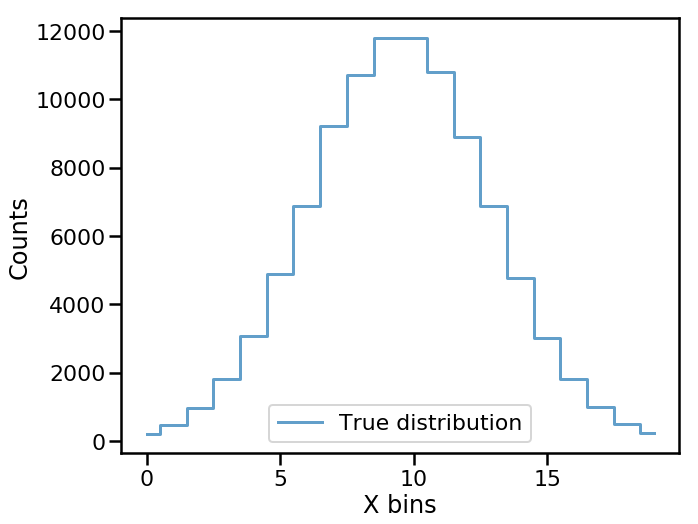
The true distribution of \(X\) looks like
In [7]:
fig, ax = plt.subplots()
ax.step(np.arange(num_bins), data_true, where='mid', lw=3,
alpha=0.7, label='True distribution')
ax.set(xlabel='X bins', ylabel='Counts')
ax.legend()
plt.show()
Observed distribution¶
Generally speaking, measurement devices aren’t perfect. This means that the measured value of \(X\) isn’t always exactly the same as the true value. That is, our measurement device has some inherit bias and resolution.
We’ll model these detection imperfections by adding some random Gaussian noise to our true values of \(X\) to get our observed (measured) values.
In [8]:
random_noise = np.random.normal(loc=0.3, scale=0.5, size=num_samples)
observed_samples = true_samples + random_noise
The observed values can be binned into a histogram. This array,
data_observed, is the distribution we want to unfold.
In [9]:
data_observed, _ = np.histogram(observed_samples, bins=bins)
data_observed
Out[9]:
array([ 201, 423, 805, 1409, 2361, 3546, 5203, 7122, 8360,
9842, 10669, 10602, 9908, 8474, 6925, 5054, 3549, 2342,
1454, 759])
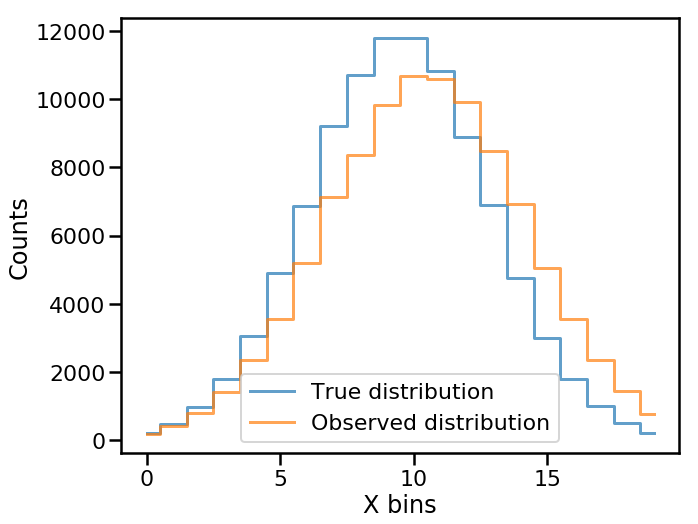
We can see how the true and observed distribution of \(X\) differ.
In [10]:
fig, ax = plt.subplots()
ax.step(np.arange(num_bins), data_true, where='mid', lw=3,
alpha=0.7, label='True distribution')
ax.step(np.arange(num_bins), data_observed, where='mid', lw=3,
alpha=0.7, label='Observed distribution')
ax.set(xlabel='X bins', ylabel='Counts')
ax.legend()
plt.show()
In addition to the observations themselves, the uncertainty of the observations is also needed to perform an unfolding. Here, we’ll assume the errors are simply Poisson counting errors (i.e. \(\mathrm{error_{i} = \sqrt{counts_{i}}}\)).
In [11]:
data_observed_err = np.sqrt(data_observed)
data_observed_err
Out[11]:
array([ 14.17744688, 20.5669638 , 28.37252192, 37.53664876,
48.59012245, 59.54829972, 72.13182377, 84.39194274,
91.43303561, 99.2068546 , 103.29085148, 102.96601381,
99.53893711, 92.05433178, 83.21658489, 71.09149035,
59.57348403, 48.39421453, 38.13135193, 27.54995463])
Detection Efficiencies¶
Not every sample from our true distribution will lead to a measured observation. The probability that a sample from our true distribution is observed is quantified via our detection efficiencies. For now, we’ll assume uniform efficiencies of 1.
In [12]:
efficiencies = np.ones_like(data_observed, dtype=float)
efficiencies
Out[12]:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1.])
Likewise, let’s assume an uncertainty on our efficiencies of 0.1.
In [13]:
efficiencies_err = np.full_like(efficiencies, 0.1, dtype=float)
efficiencies_err
Out[13]:
array([0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1])
Response matrix¶
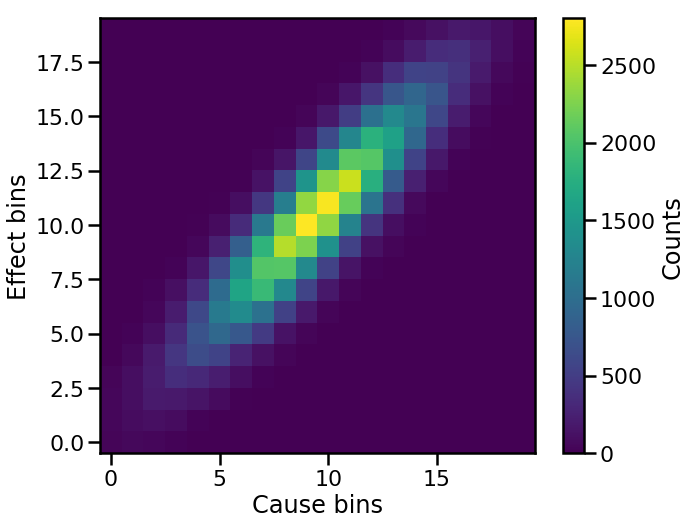
The next step is to construct a response matrix that encapsulates our detector bias and resolution. This can be done by making a 2-dimensional histogram of the true vs. observed distributions.
In [14]:
response_hist, _, _ = np.histogram2d(observed_samples, true_samples, bins=bins)
As with the uncertainties on our observed data, we’ll assume Poisson counting errors for our response matrix.
In [15]:
response_hist_err = np.sqrt(response_hist)
In [16]:
fig, ax = plt.subplots()
im = ax.imshow(response_hist, origin='lower')
cbar = plt.colorbar(im, label='Counts')
ax.set(xlabel='Cause bins', ylabel='Effect bins')
plt.show()
However, there’s still one more step for the response matrix. What’s
needed for unfolding is not this 2-d counts histogram, but a matrix with
the conditional probabilities \(P(E_i|C_j)\). This matrix, called
the normalized response matrix, can be obtained by normalizing our 2-d
counts matrix. That is, scale each column of response_hist such that
it adds to our detection efficiencies.
This normalization factor can be easily found via:
In [17]:
column_sums = response_hist.sum(axis=0)
normalization_factor = efficiencies / column_sums
In [18]:
response = response_hist * normalization_factor
response_err = response_hist_err * normalization_factor
As a check we can see that the columns of response add to our
detection efficiencies.
In [19]:
response.sum(axis=0)
Out[19]:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1.])
We can see how the structure of the 2-d response histogram differs from the normalized response matrix.
In [20]:
fig, ax = plt.subplots()
im = ax.imshow(response, origin='lower')
cbar = plt.colorbar(im, label='$P(E_i|C_{\mu})$')
ax.set(xlabel='Cause bins', ylabel='Effect bins',
title='Normalizes response matrix')
plt.show()
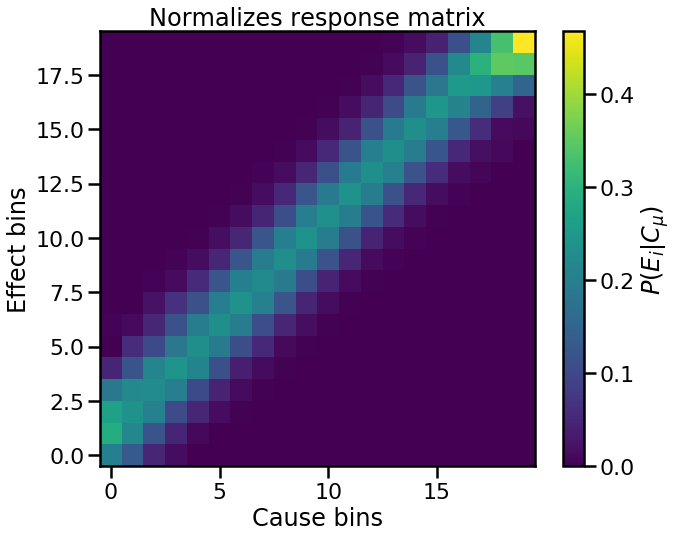
This difference in structure is because each column in the normalized response matrix is scaled by the number of samples in that column. So only the relative structure of each column of the 2-d response histogram is present in the normalized response matrix.
Iterative unfolding¶
Now we have everything we need to perform our unfolding:
- Observed distribution to unfold (with uncertainties):
data_observed,data_observed_err - Detection efficiencies (with uncertainties):
efficiencies,efficiencies_err - Normalized response matrix (with uncertainties):
response,response_err
These are all input parameters into the PyUnfold iterative_unfold
function.
In [21]:
unfolded_results = iterative_unfold(data=data_observed,
data_err=data_observed_err,
response=response,
response_err=response_err,
efficiencies=efficiencies,
efficiencies_err=efficiencies_err,
callbacks=[Logger()])
Iteration 1: ts = 0.1405, ts_stopping = 0.01
Iteration 2: ts = 0.0370, ts_stopping = 0.01
Iteration 3: ts = 0.0122, ts_stopping = 0.01
Iteration 4: ts = 0.0045, ts_stopping = 0.01
What’s returned from iterative_unfold is a dictionary that contains:
- Unfolded distribution (
unfoldedkey) - Statistical uncertainties on the unfolded distribution (
stat_errkey) - Systematic uncertainties on the unfolded distribution based on the
response matrix uncertainties (
sys_errkey) - Number of unfolding iterations to reach test statistic stopping
condition (
num_iterationskey) - Test statistic value for final iteration (
ts_iterkey) - Test statistic stopping condition (
ts_stoppingkey) - Unfolding matrix (
unfolding_matrixkey)
In [22]:
unfolded_results.keys()
Out[22]:
dict_keys(['num_iterations', 'stat_err', 'sys_err', 'ts_iter', 'ts_stopping', 'unfolded', 'unfolding_matrix'])
In [23]:
unfolded_results['unfolded']
Out[23]:
array([ 310.86521388, 510.24984975, 975.93115866, 1820.17860556,
3102.11778019, 4879.85122145, 7015.52494748, 8981.07735716,
10707.88612751, 11730.53337574, 11728.54653455, 10756.91277901,
8984.92352888, 6837.92414987, 4606.18470207, 2858.77526528,
1512.64260778, 868.22035667, 500.28580382, 319.36863468])
In [24]:
unfolded_results['sys_err']
Out[24]:
array([ 46.20897611, 65.68431793, 120.33554668, 201.02566916,
300.50353578, 396.6598952 , 487.03457737, 534.88778388,
579.5283416 , 592.75528923, 582.1886126 , 580.96624808,
549.87854794, 493.35713996, 405.72190552, 300.92531524,
186.67615767, 118.274722 , 73.06780024, 51.66847962])
Finally, we can see how the true, observed, and unfolded distributions compare to one another.
In [25]:
fig, ax = plt.subplots()
ax.step(np.arange(num_bins), data_true, where='mid', lw=3,
alpha=0.7, label='True distribution')
ax.step(np.arange(num_bins), data_observed, where='mid', lw=3,
alpha=0.7, label='Observed distribution')
ax.errorbar(np.arange(num_bins), unfolded_results['unfolded'],
yerr=unfolded_results['sys_err'],
alpha=0.7,
elinewidth=3,
capsize=4,
ls='None', marker='.', ms=10,
label='Unfolded distribution')
ax.set(xlabel='X bins', ylabel='Counts')
plt.legend()
plt.show()
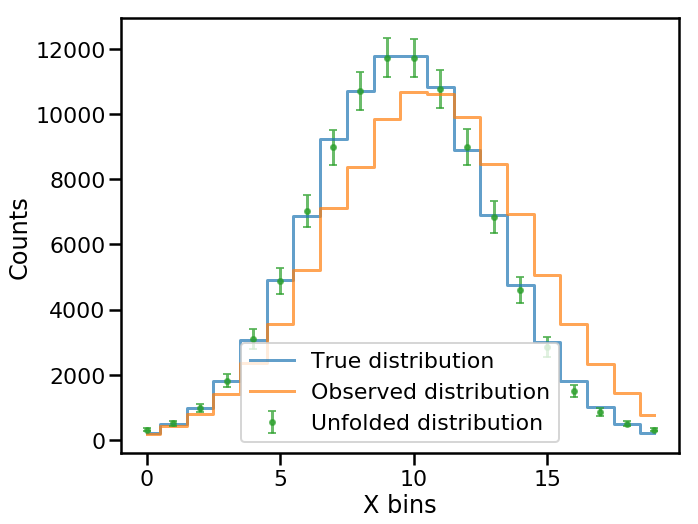
Note that the unfolded distribution is consistent with the true distribution!